A Comparative Study on First Order Optimization Algorithms
Brief
In this project, I implemented and compared several first-order optimization algorithms from scratch, including Steepest Descent (Gradient Descent with Line-Search), Momentum Gradient Descent, and Nesterov Accelerated Gradient Descent (NAGD). I also developed a custom Armijo backtracking line search to determine adaptive step sizes. These algorithms were then tested across convex and non-convex functions, as well as on a signal denoising task, to analyze their convergence behavior and robustness.
Details
The study begins with the classical Steepest Descent and Momentum Gradient Descent methods. Momentum improves upon the standard approach by incorporating a velocity term that helps the optimizer maintain direction and accelerate through shallow regions.
Nesterov’s Accelerated Gradient Descent (NAGD) refines this idea further by predicting the next position before computing the gradient, leading to faster convergence and improved handling of ill-conditioned functions. The algorithm’s dynamics are governed by:
\[ x_{i+1} = y_i - \tau_i \nabla f(y_i) \] \[ y_{i+1} = x_{i+1} + \frac{\lambda_i - 1}{\lambda_{i+1}} (x_{i+1} - x_i) \]where the momentum parameter \( \lambda_i \) evolves according to:
\[ \lambda_0 = 0, \quad \lambda_{i+1} = \frac{1 + \sqrt{1 + 4\lambda_i^2}}{2} \]To ensure convergence and stability, I implemented an Armijo Backtracking Line Search. This strategy adaptively selects the step size \( \tau \) based on a sufficient decrease condition:
\[ f(x) \leq f(y) + \langle \nabla f(y), x - y \rangle + \frac{1}{2\tau} \|x - y\|^2 \]The step size \( \tau \) is chosen as:
\[ \tau = \frac{1}{2^m}, \quad \text{where } m \text{ is the smallest integer for which the condition holds.} \]I applied this framework to a variety of test scenarios, including convex functions, non-convex functions, and a real-world signal denoising task. Each algorithm’s performance was assessed based on convergence speed, stability, and accuracy. NAGD consistently demonstrated superior behavior in terms of stability and fast convergence.
Rotated Hyper-Ellipsoid Function
This convex benchmark function is defined as:
\[ f(x) = \sum_{i=1}^{n} \left( \sum_{j=1}^i x_j \right)^2, \quad n = 10, 100 \]It has a global minimum at the origin:
\[ f(0,0,\dots,0) = 0 \]The stopping criterion used was:
\[ |f(x_n) - f(x_{n-1})| < 10^{-6} \]Results Table
| Scheme | Iterations (N=10) | Value | Iterations (N=100) | Value |
|---|---|---|---|---|
| Steepest Descent | 407 | 7.188e-5 | 23304 | 0.008 |
| SD with Momentum | 101 | 2.816e-5 | 3833 | 0.001 |
| NAGD Fixed | 91 | 0.0001 | 1609 | 0.0003 |
| NAGD | 65 | 0.0007 | 673 | 0.0007 |
Ackley's Function
The Ackley function is defined as:
\[ f(\mathbf{x}) = -a \exp \left( -b \sqrt{\frac{1}{d} \sum_{i=1}^{d} x_i^2} \right) - \exp \left( \frac{1}{d} \sum_{i=1}^{d} \cos(c x_i) \right) + a + \exp(1) \]where \( a = 20 \), \( b = 0.2 \), \( c = 2\pi \). This is a non-convex function commonly used to test convergence behavior of optimizers.
Results Table
| Method | Iterations | Gradient Norm |
|---|---|---|
| Nesterov w/o line search (fixed param) | 25 | 1.263e-07 |
| Nesterov w/o line search | 33 | 2.718e-05 |
| Momentum Gradient Descent | 86 | 9.608e-07 |
| Vanilla Gradient Descent | 55 | 8.291e-07 |
Trajectories
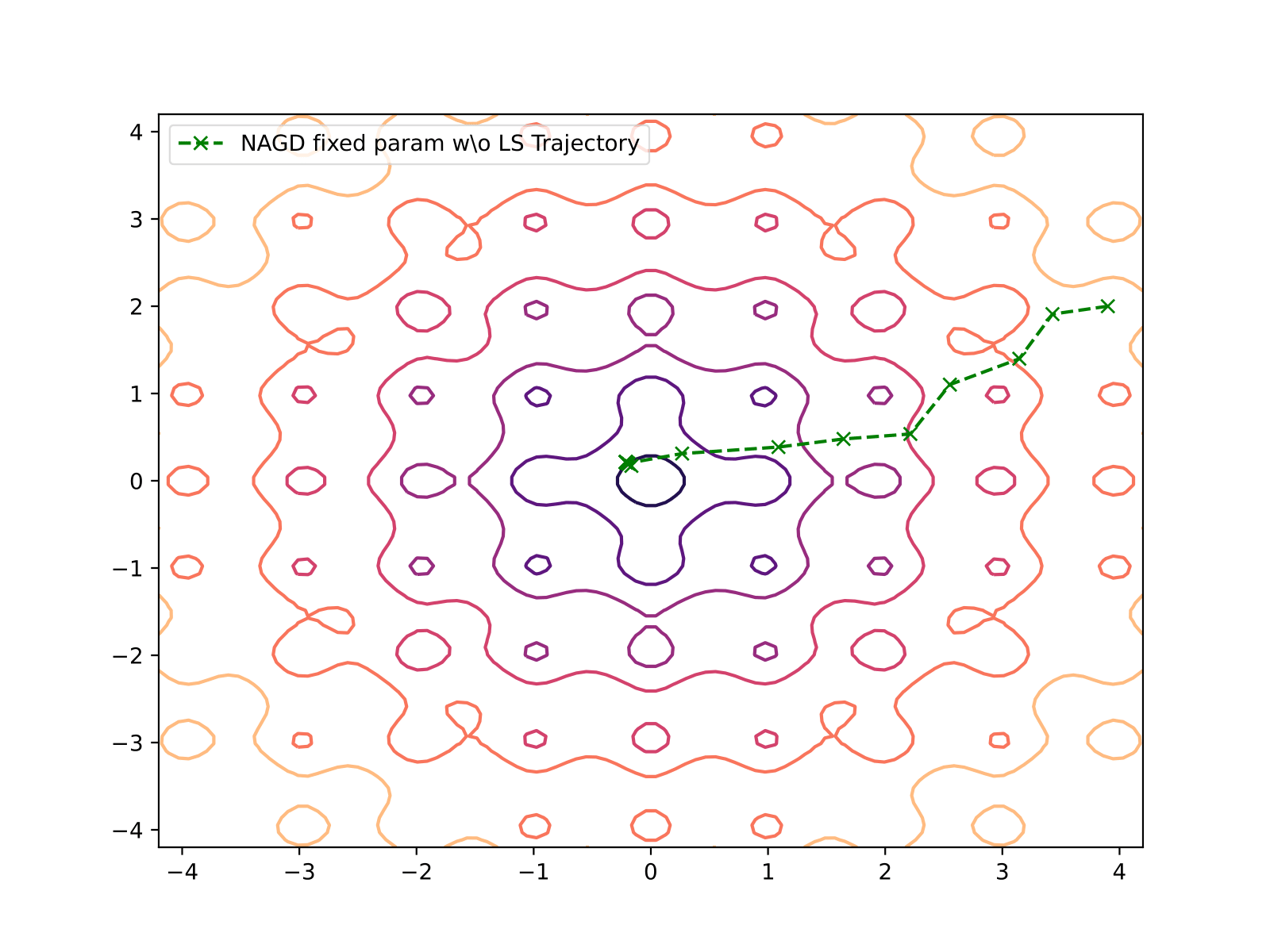
Nesterov w/o Line Search (Fixed Parameter)
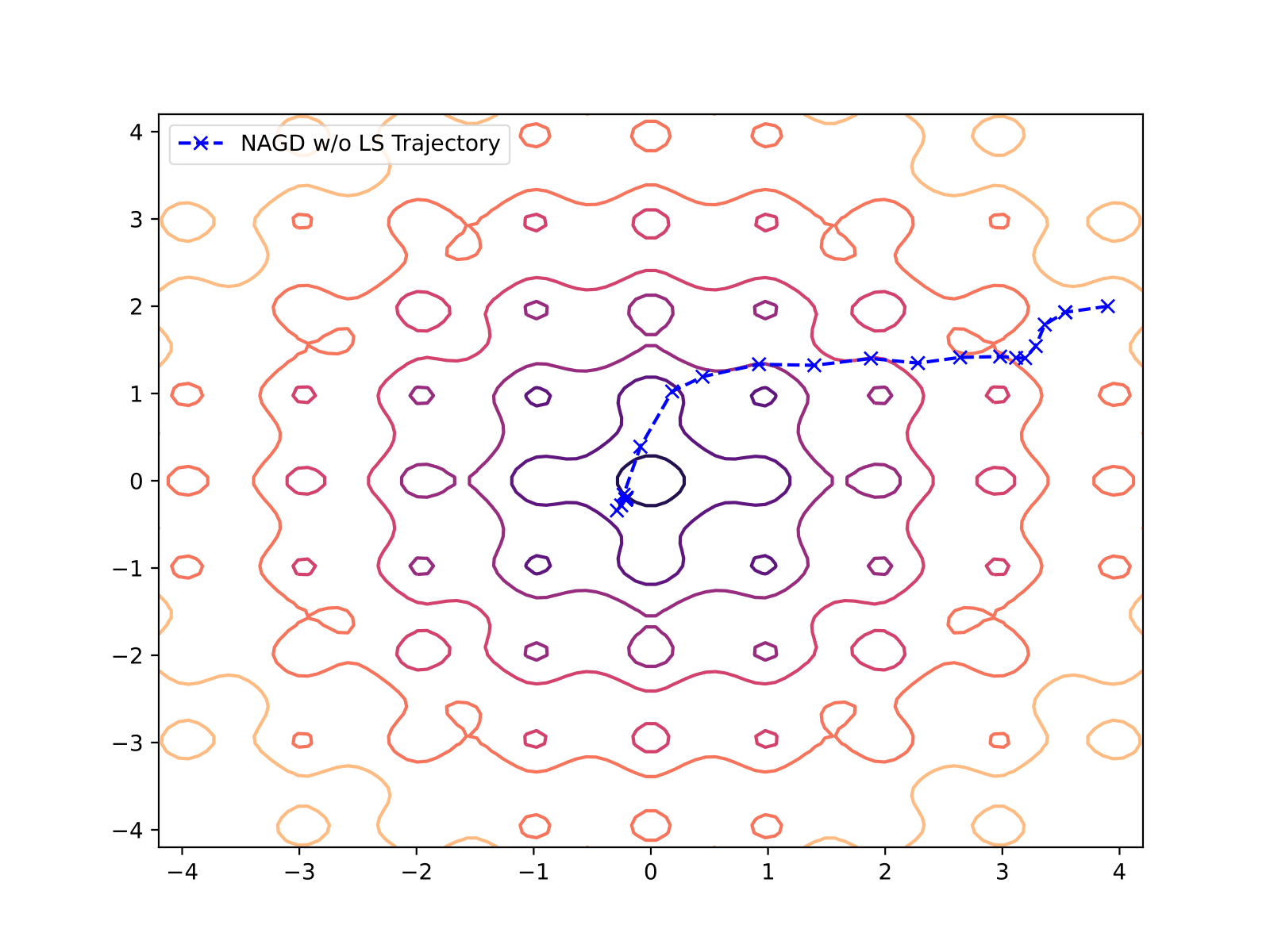
Nesterov w/o Line Search
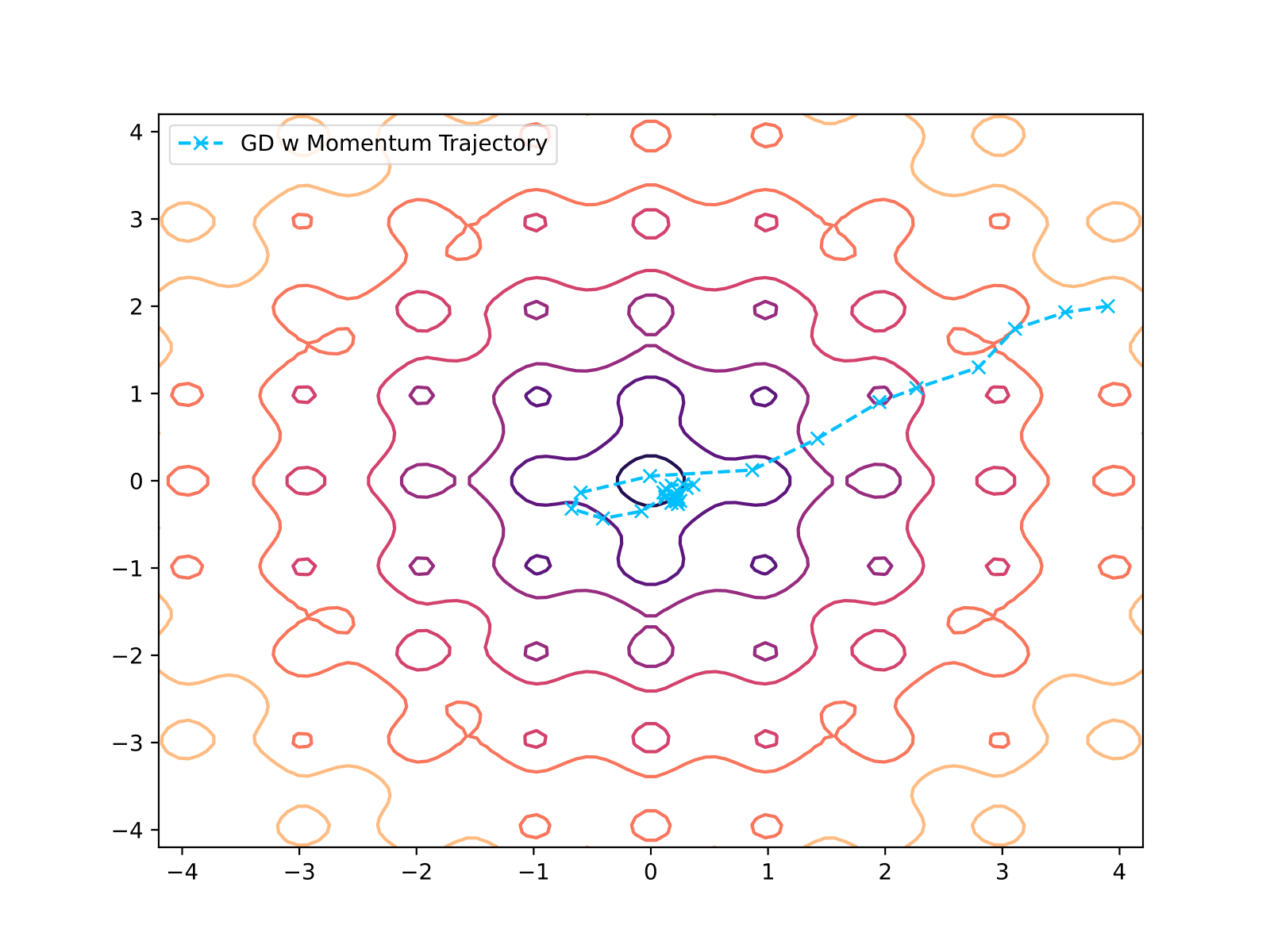
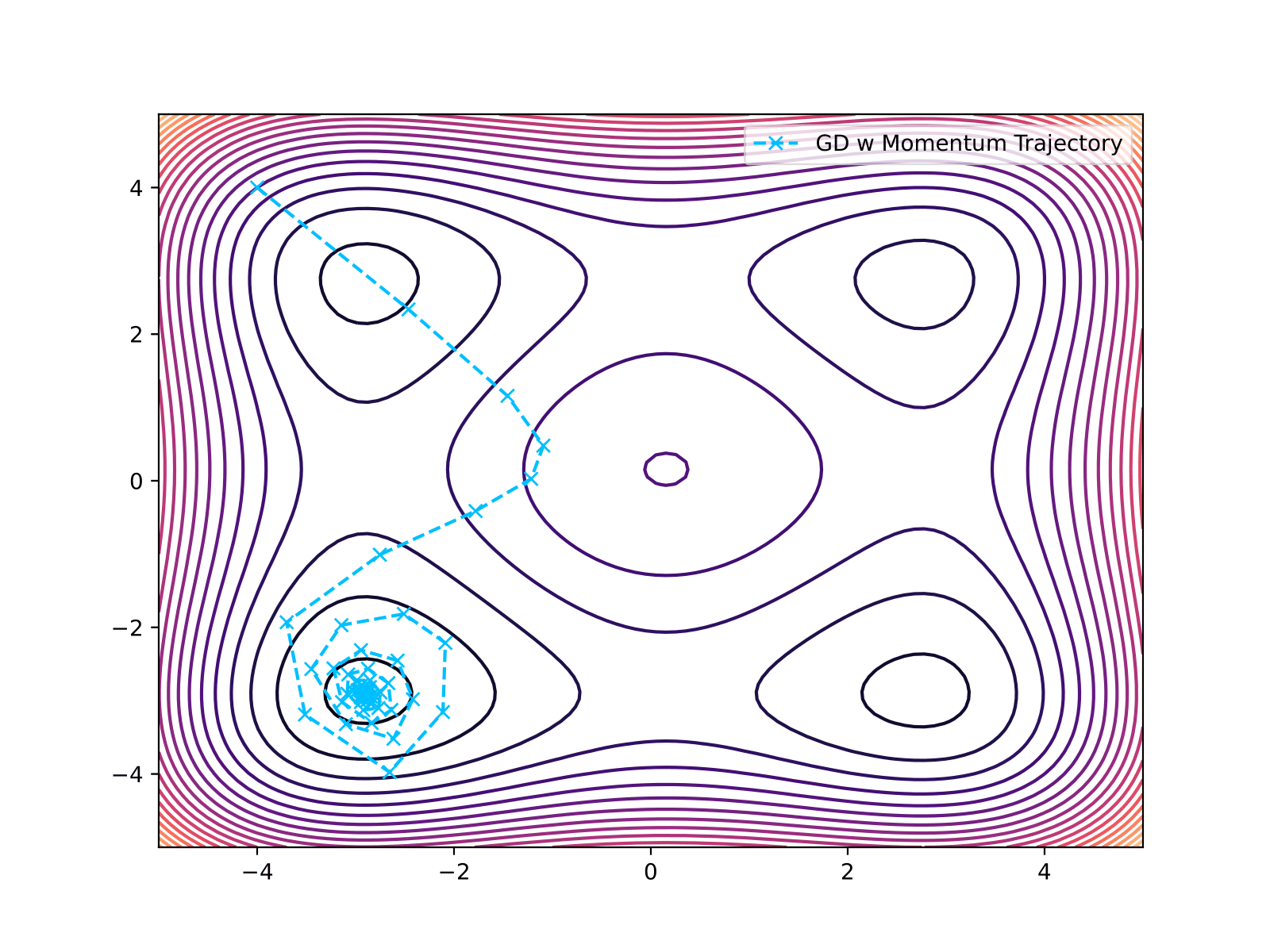
Momentum Gradient Descent
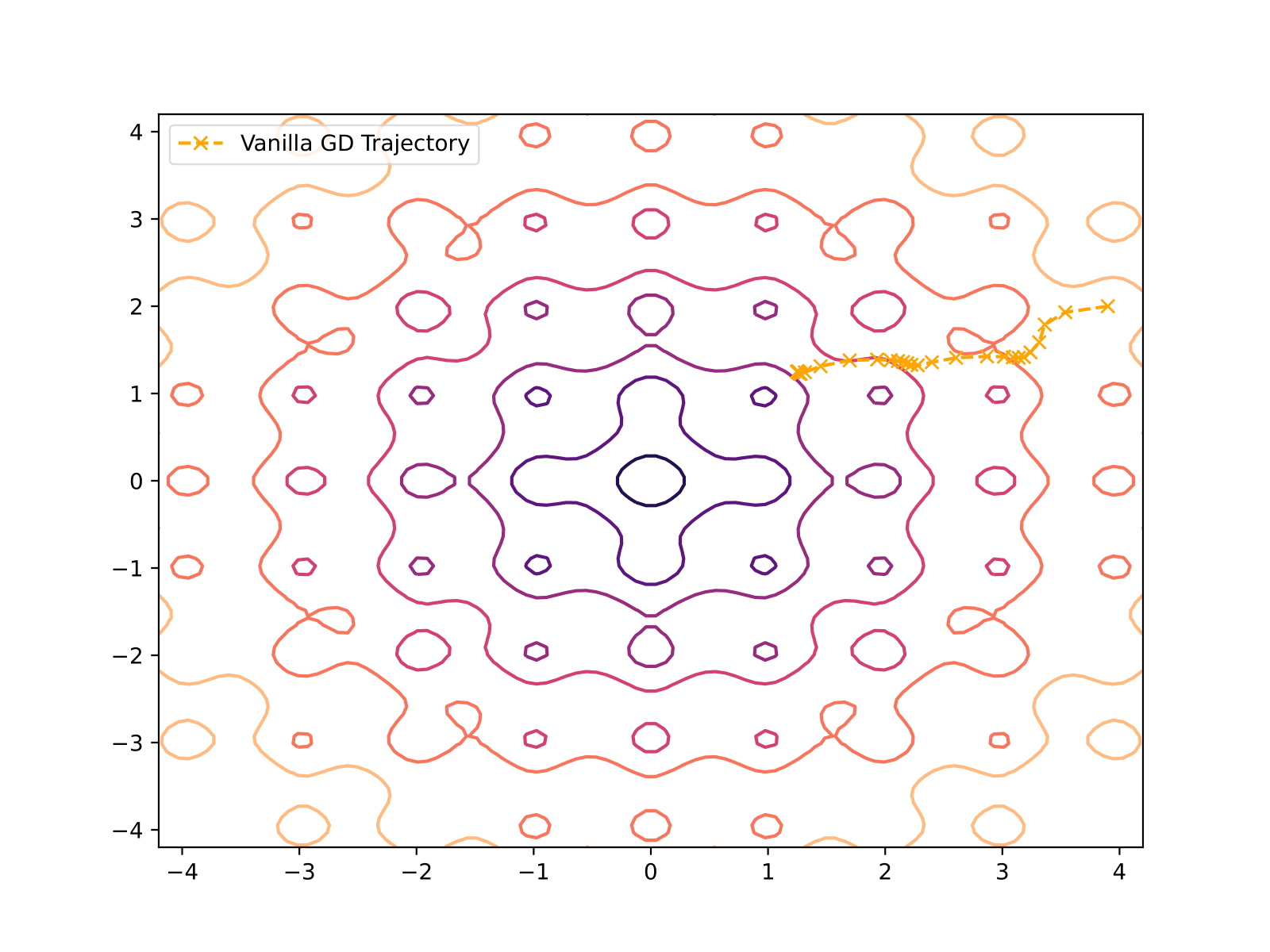
Vanilla Gradient Descent
Styblinski–Tang Function
The Styblinski–Tang function is defined as:
\[ f(\mathbf{x}) = \sum_{i=1}^{d} \left( \frac{x_i^4 - 16x_i^2 + 5x_i}{2} \right) \]This function has four local minima and one global minimum, making it useful for evaluating the performance of optimizers on non-convex landscapes.
Results Table
| Method | Iterations | Minimum Value |
|---|---|---|
| Nesterov with Line Search (Variable Param) | 9 | 4.563e-04 |
| Nesterov w/o Line Search (Fixed Param) | 14 | 9.758e-04 |
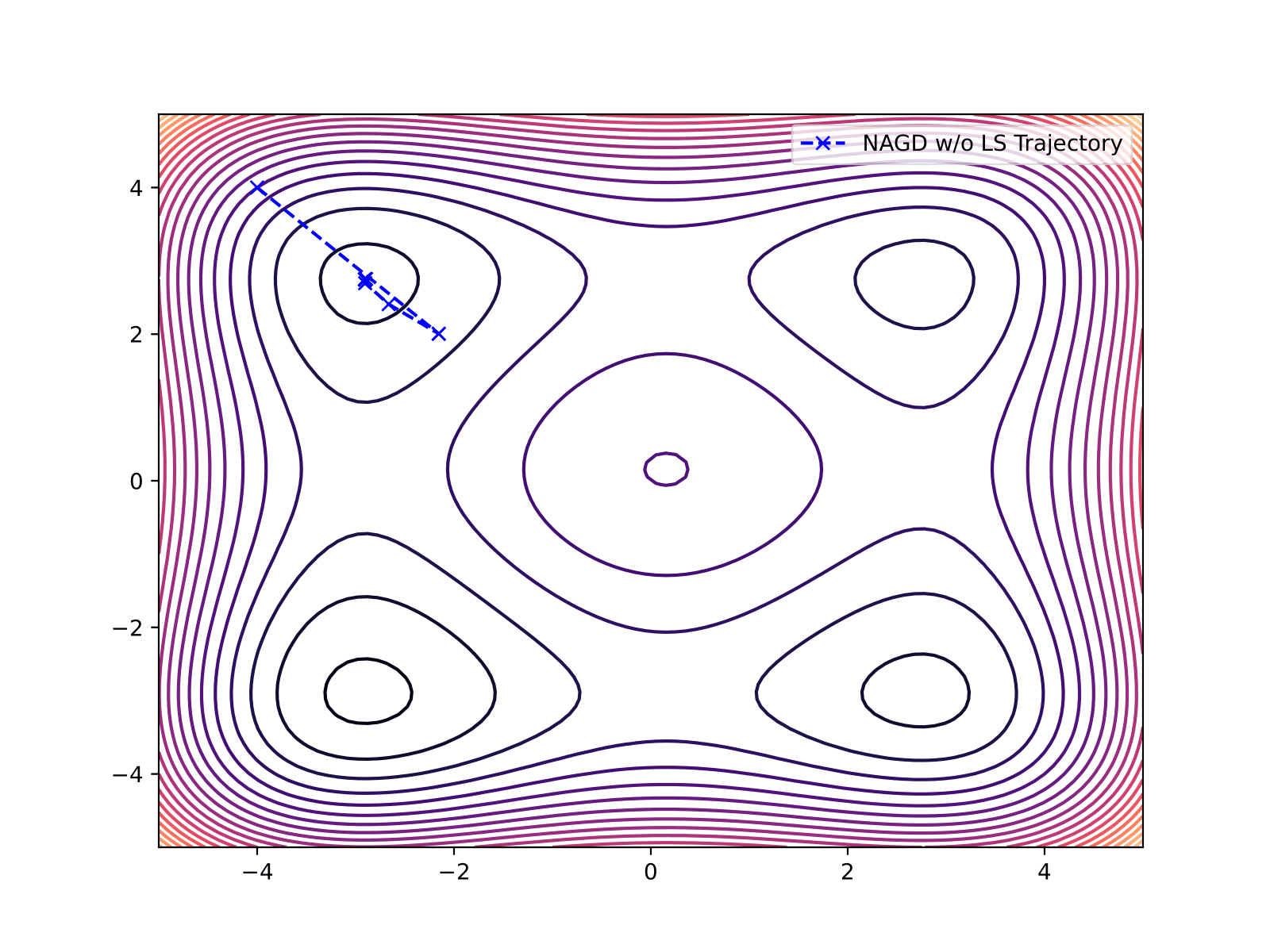
| Nesterov w/o Line Search | 10 | 1.774e-04 |
| Gradient Descent with Momentum | 104 | 5.630e-05 |
Optimization Trajectories
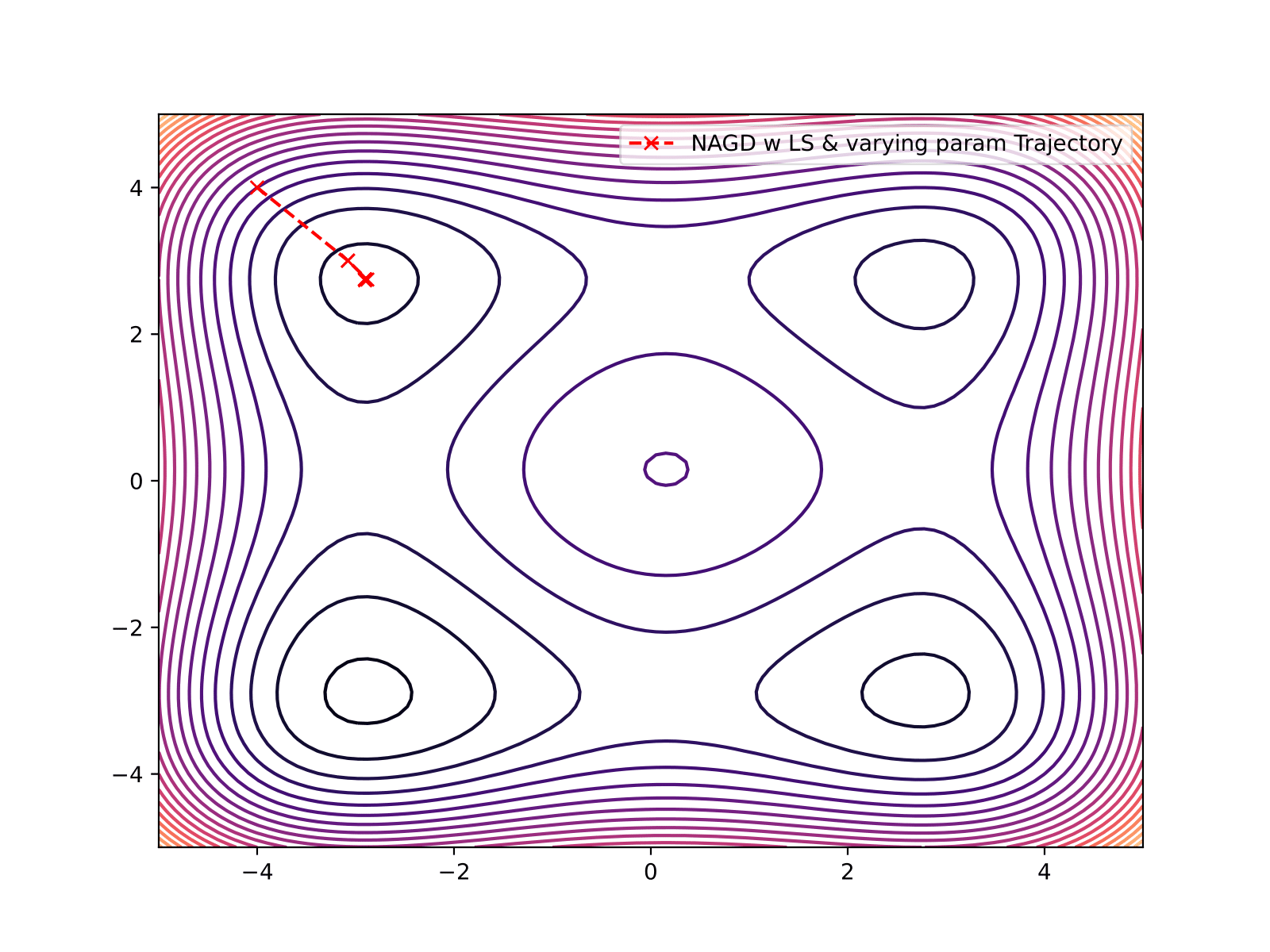
Nesterov with Line Search (Variable Parameter)
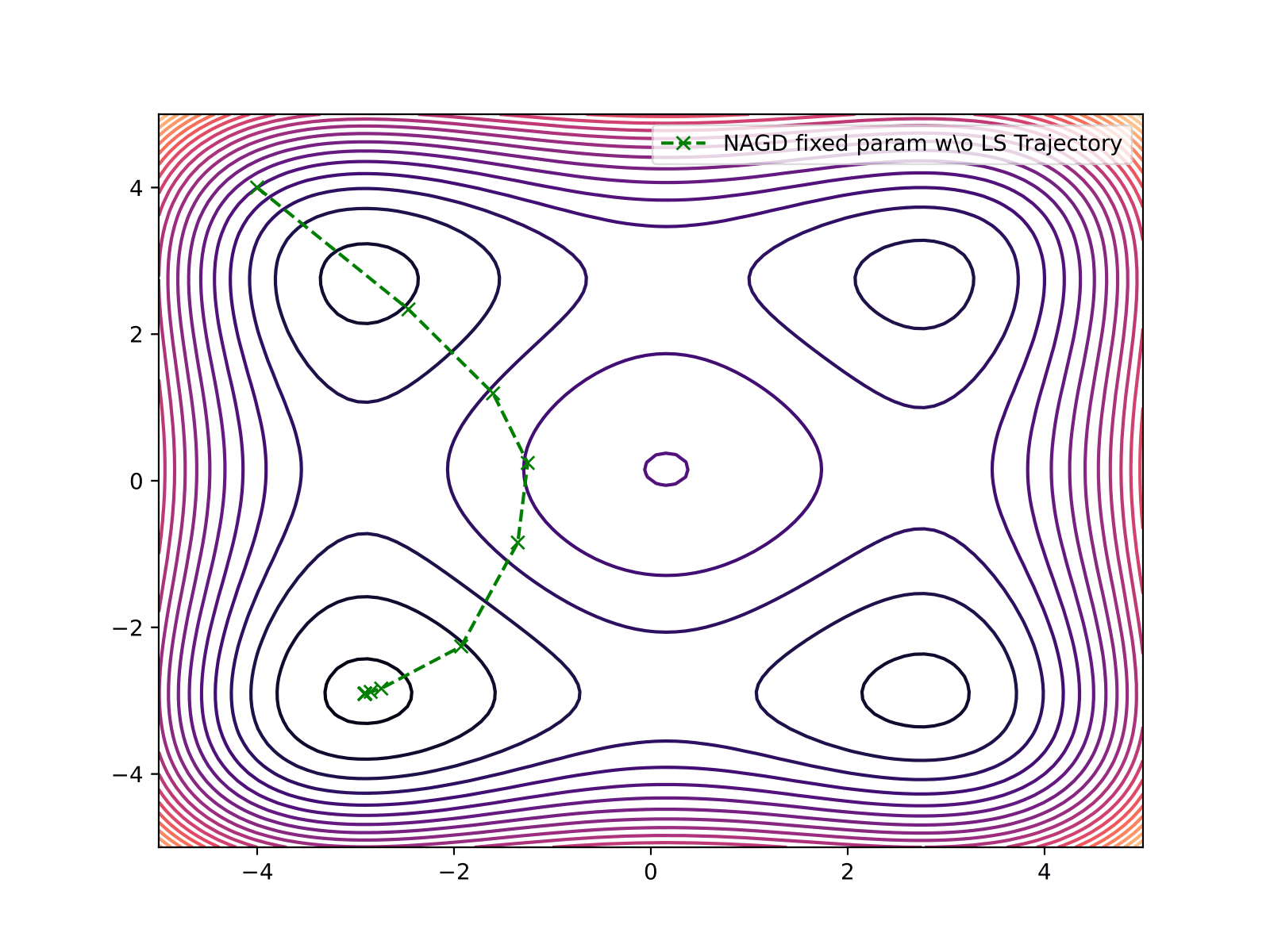
Nesterov Fixed Parameter (w/o Line Search)
Momentum Gradient Descent
Vanilla Gradient Descent